- Published on
How much would it cost to store a 1 hour, 60fps 4k Video in a RAG model?
- Authors

- Name
- Athos Georgiou

Welcome to my mad little experiment
For a few days I've been pondering for simple ways to build a RAG model for VTT, (Video to Text), where a user could have a discussion with their uploaded videos. But when I did some super duper napkin math, It freaked me out a little. So, I thought I'd share it with you, in case you're mad enough to try it.
Keep in mind I'm not taking time as a factor in the calculations, as it may vary quite significantly, depending on the hardware and the software used.
Le Mad Experiment
- Upload a 1 hour, 4k, 60 fps Video to a RAG application.
- Break down the video in frames using fluent-ffmpeg, or similar.
- Send each frame to OpenAI's gpt-4-1106-vision-preview with a prompt to describe the frame in as much detail as possible.
- Store the output in a file.
- Parse/Chunk the file using a parser, such as Unstructured.io.
- Embed each chunk using text-embedding-3-small
- Store the embedded chunks in a Vector Database, such as Pinecone Serverless.
Ingesting the Video
As per the OpenAI pricing, the cost of using the gpt-4-1106-vision-preview model is $0.01 / 1K tokens for input..
Let's be bold. We go for 4k video, 60fps, 60 minutes long.
Using the Vision pricing calculator, let's calculate the cost for 1 frame of 4k video (4096px by 2160px):
- Price per 1K tokens (fixed): $0.01
- Resized width: 1456
- Resized height: 768
- 512 × 512 tiles: 3 × 2
- Total tiles: 6
- Base tokens: 85
- Tile tokens: 170 × 6 = 1020
- Total tokens: 1105
- Total price: $0.01105
That doesn't look so bad, right? But wait, We're just getting started:
- At 60fps, that's 3600 frames per minute.
- At 60 minutes, that's 216,000 frames.
- At $0.01105 per frame, that's $2,387.4
- Output is at $0.03 per 1K tokens. For simplicity, let's assume the output is 250 tokens per frame. That's 54,000,000 tokens, or $1,620.00
- Total cost of ingesting the video: $4,007.4
The cost above is just the cost of ingesting the video. It doesn't include the cost of parsing, embedding, storing the data in a Vector Database, or inference. Let's move on to the next step.
Save the Output to a File
Let's save the output to a file. I'm going to assume that we'll store around 250 tokens in each page.
- 216,000 frames at 1105 tokens per frame: 238,680,000 tokens
- At 250 tokens per page, that's 954,720 pages
Now we're ready to parse the data.
Parsing the Data
I'm going to use the costs from Unstructured.io, which I believe are quite generous:
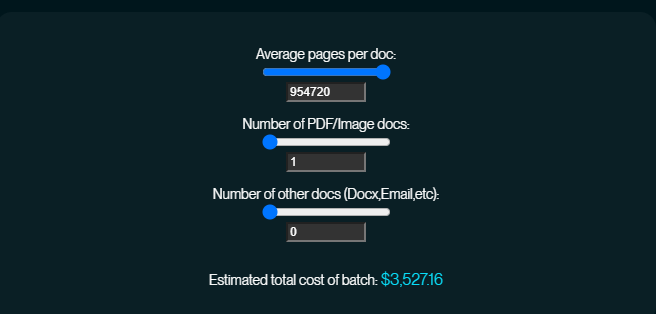
- Pages: 954,720
- Estimated cost: $3,527.16
From previous experiments, a 100 page document would produce around 40,000 chunks with most settings at default. We'll use this as a rough estimate for the number of chunks we'll have to embed and index.
We're now ready to ingest the data into a Vector Database.
Embedding the Chunks
Now we're ready to embed the data (In a naive way, assuming each parsed chunk is embedded in its entirety)
- Embedding cost: $0.00002 per 1,000 tokens
- Tokens: 238,680,000
- Total cost of embedding: $4.7736
Indexing the Chunks
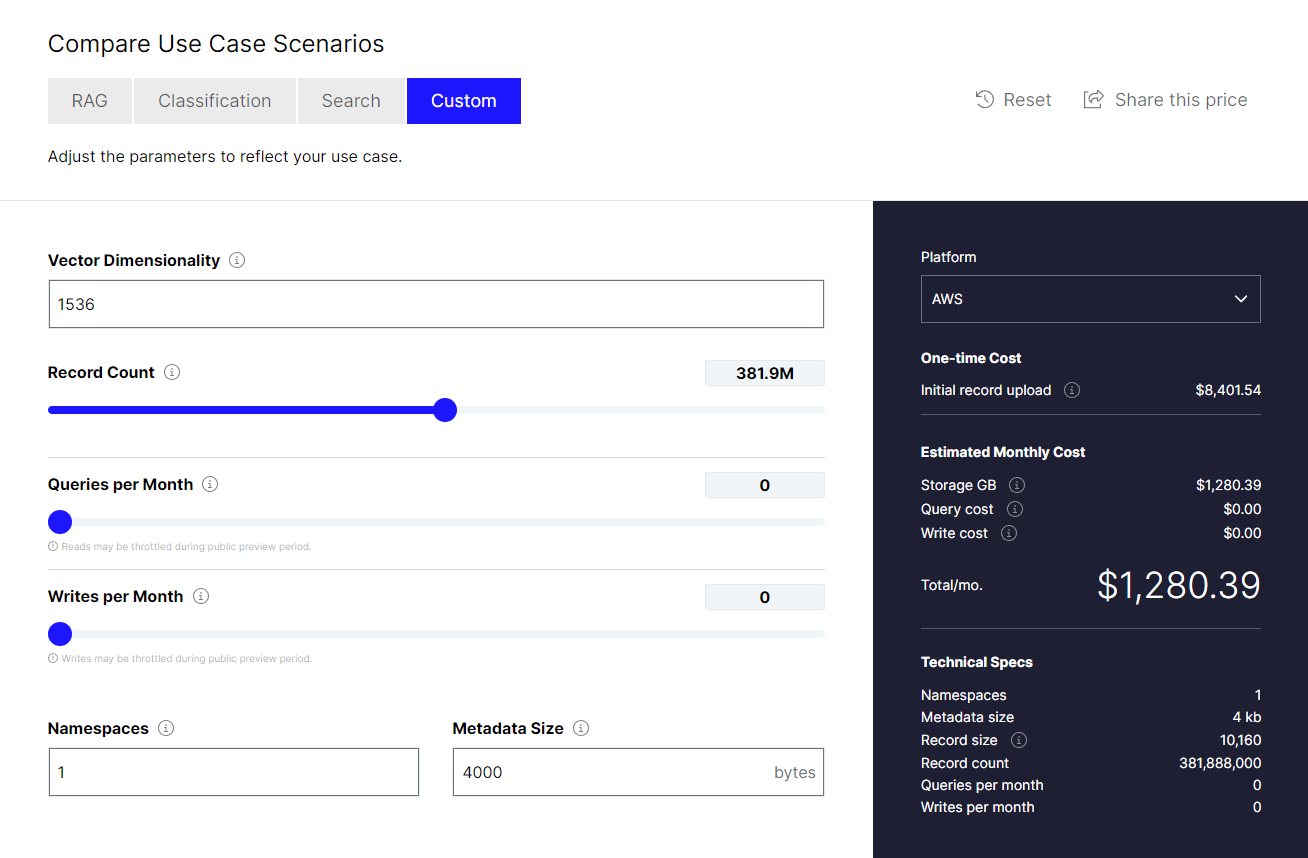
- At 954,720 pages, that's 381,888,000 chunks.
- That would cost $8,401.54 on for the initial record upload and $1,329.39 for the monthly storage.
- Total cost of indexing the video: $9,730.83
Total Cost
Total cost of ingesting + parsing + embedding + indexing the video: $17,269.09
But...
But what if we only need 1 frame per second? What would be the cost then? To simplify things, let's just divide the cost by 60:
- $17,269.09 / 60 = $287.82
Eh, somewhat more reasonable, ey?
Closing Thoughts
Essentially, the cost of storing a 1 hour, 60fps 4k Video in a RAG model in this experiment is around $17,269.09. When we reduce the frame rate to 1 frame per second, the cost is around 287.82, which is still quite a lot for a single upload, but much more manageable. Off course, there are many different ways to go about this, and the costs could be reduced significantly by using different models, or by using different hardware. But, as the saying goes, Quality = Time + Money. This is why nobody eats home cooked meals anymore!
If I get the time, I'll implement a simple version of this experiment in Titanium and share it results with you in another post.
I hope this crazy experiment was as entertaining to read, as it was to write. If you have any questions, suggestions, or have found any error in the calculations, feel free to reach out to me on GitHub, LinkedIn, or via email.
Until next time, take care, and don't forget your (number) crunches!